Setup
This tutorial is about recognizing objects in images or video streams. The YOLO framework is used for this purpose. YOLO offers a very simple and extremely high-performance option for object classification. We will use OpenCV to control the camera and preprocess the images.
OpenCV

OpenCV (Open Source Computer Vision Library) is an open source computer vision and machine learning software library. OpenCV was built to provide a common infrastructure for computer vision applications and to accelerate the use of machine perception in the commercial products. Being an Apache 2 licensed product, OpenCV makes it easy for businesses to utilize and modify the code. To install OpenCV, simply execute the following command:
Pip install opencv-python
Camera Test
Accessing the camera is extremely easy; OpenCV provides easy-to-use methods for this purpose. The only important thing is to find out the camera number: the “VideoCapture” method requires the index of the camera to be used. Normally, every built-in camera (in a laptop or tablet) has the index 0, while an external camera (e.g., USB camera) has the index 1.
import cv2
from ultralytics import YOLO
# Open the video stream
cam = cv2.VideoCapture(0)
# Loop through the video frames
while cam.isOpened():
# Read a frame from the video
success, frame = cam.read()
if success:
# Display the annotated frame
cv2.imshow("TEST", frame)
# Break the loop if 'q' is pressed
if cv2.waitKey(1) == ord("q"):
break
else:
# Break the loop if the end of the video is reached
break
# Release the video capture object and close the display window
cam.release()
cv2.destroyAllWindows
YOLO
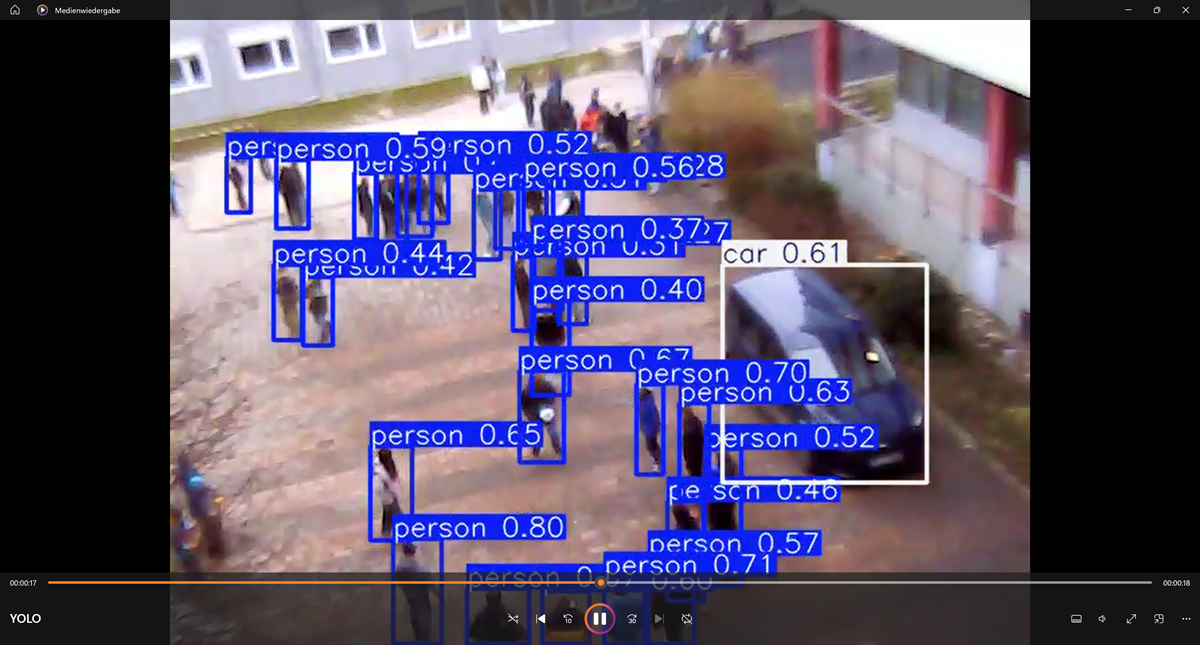
YOLO stands for You Only Look Once, a family of real-time object detection algorithms. It is widely used in computer vision tasks to identify and locate objects within images or video streams. YOLO is known for its speed and efficiency, making it suitable for applications requiring real-time processing, such as surveillance, autonomous vehicles, and robotics. As illustrated below, it has 24 convolutional layers, four max-pooling layers, and two fully connected layers.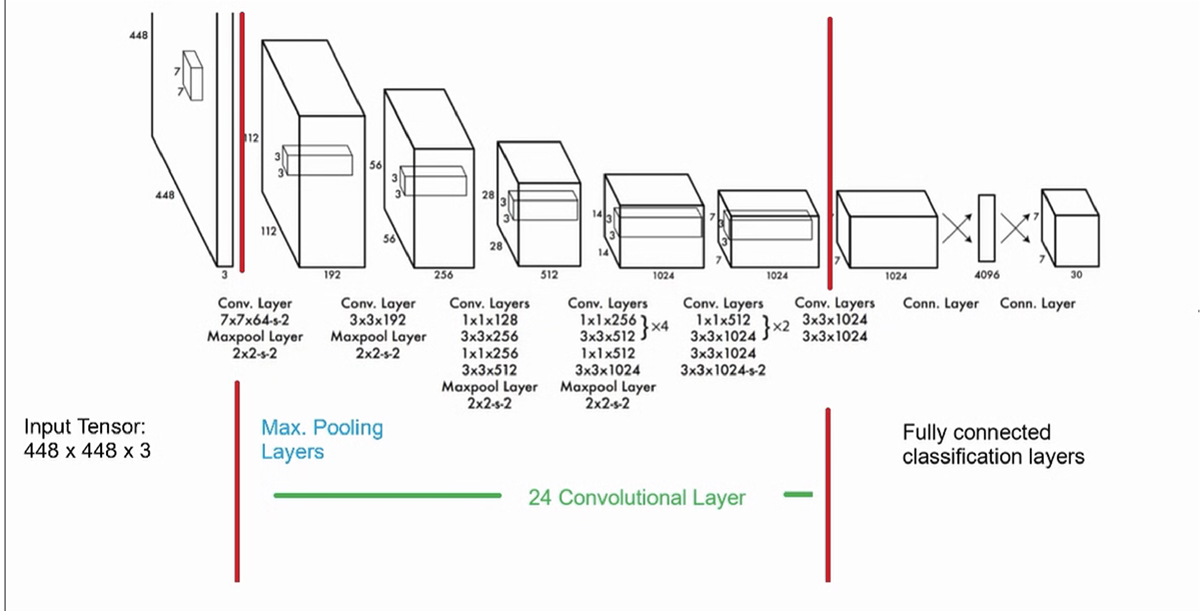
The first 20 convolution layers of the model are pre-trained using ImageNet by plugging in a temporary average pooling and fully connected layer. Then, this pre-trained model is converted to perform detection since previous research showcased that adding convolution and connected layers to a pre-trained network improves performance. YOLO’s final fully connected layer predicts both class probabilities and bounding box coordinates.
YOLO divides an input image into an S × S grid. If the center of an object falls into a grid cell, that grid cell is responsible for detecting that object. Each grid cell predicts B bounding boxes and confidence scores for those boxes. These confidence scores reflect how confident the model is that the box contains an object and how accurate it thinks the predicted box is.

YOLO models, including yolo11n.pt, are commonly trained on the COCO dataset. The COCO dataset (short for Common Objects in Context) is a widely used large-scale dataset for training and evaluating computer vision models. It was developed by researchers at Microsoft and is designed to advance the understanding of objects in complex, real-world scenes.
YOLO Installation
As always, you can easily install YOLO with pip:
pip install ultralytics